Brand Intelligence for the Age of AI
Ihre Marke muss heute zuerst die KI überzeugen - dann den Kunden.
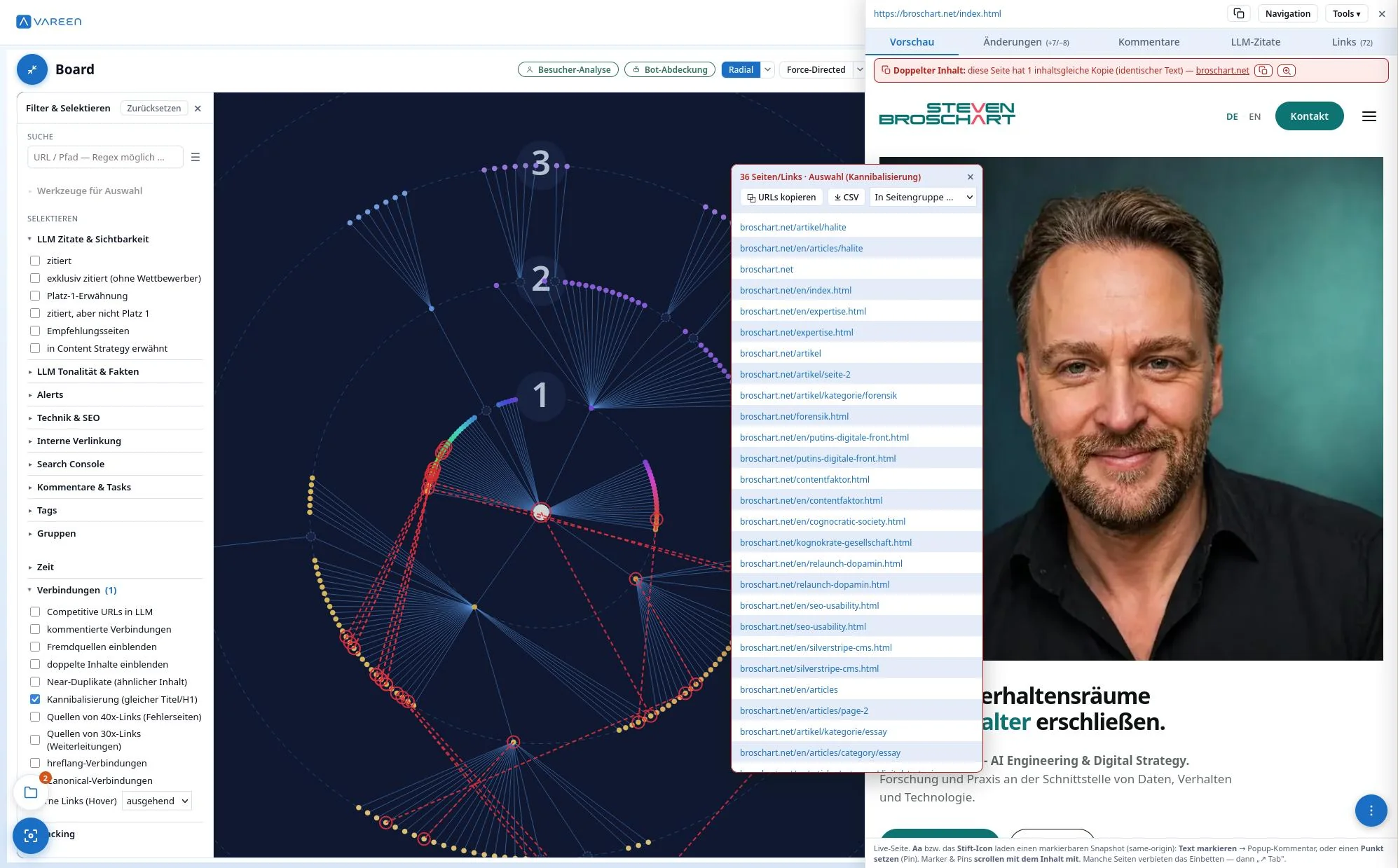
Zwischen Ihrer Marke und dem Markt steht heute ein neuer Gatekeeper: künstliche Intelligenz. Sie formt Wahrnehmung, Vertrauen und Relevanz, bevor Menschen entscheiden.
Ihre Website ist damit nicht mehr nur Ziel menschlicher Aufmerksamkeit, sondern zunehmend Quelle maschineller Einordnung. Inhalte, Struktur und Signale entscheiden, wie KI Ihre Marke versteht und weitergibt.